– Der Colordaemon war da! –

Heute geht es mal wieder um Linux. Und nur am Rande um den Colordaemon, ein Daemon, also ein Hintergrundprozess, der sich, wie meist, durch ein kleines D am Namensende verrät. Wobei es auch ein, zwei Dämonen gibt, sich nicht so verraten, und natürlich gibt es Programme, die zufällig auf ‚d‘ enden, ohne dass sie damit signalisieren wollen, dass sie Dämonen sind. Also ein Fall, wie geschaffen, um den Unterschied zwischen starken Indizien von Beweisen zu erläutern, wüssten nicht mehr Leute, was Indizien und Beweise sind, als was Dämonen unter unixoiden Systemen sind.
Andere, mehr oder weniger bekannte Dämonen, sind der Druckerdaemon cupsd des common unix printing service, sowie dbus-daemon, avahi-daemon, die auf andere Weise ihre Dämonenhaftigkeit äußern, aber ich verrate jetzt nicht wie, usb-storage und cron sind wohl auch Dämonen, und haben kein D am Ende. Cron spielt noch eine Rolle am Rande. Dagegen wären sed und thunderbird Programme, die trotz D-Endung keine sind.
Wen’s interessiert, ps ax -o cmd gibt die Namen aller laufenden Prozesse aus.
Das eigentliche Thema hier sind aber weder Dämonen, noch der colord im Besonderen, sondern das syslog, Scheduler und Orage. Ein Scheduler ist ein Zeitplaner und Orage ist der Zeitplaner, um den es hier geht.
Motivation:
Oft wollen Leute, dass das System sie regelmäßig über Dinge informiert, und sie wollen es auf dem Desktop sehen. Dabei treffen sie auf Linuxexperten, die oft beruflich oder ehrenamtlich Sysadmin sind, und für solche Aufgaben die seit den 60ern bewährten Programme cron/anachron benutzen (anacron ist ein anachronististischer cron, habe ich mir sagen lassen), aber diese arbeiten befehlszeilenorientiert und werden über superschlanke, jedoch leicht kryptische Tabellen, die crontabs, konfiguriert – das ist schon nicht jedermanns Sache.
Außerdem laufen sie vom Systemstart weg, noch bevor die grafische Umgebung, X11 und der ganze Desktopkrempel geladen ist und nicht mit den Rechten des Users. Auf Servern läuft meist gar keine Desktopumgebung und folglich sind sie nicht sonderlich dafür ausgelegt, dem User, der womöglich gar nicht angemeldet ist, der auch kein DE (Desktop-Environment) geladen hat, eine Popupnachricht zu senden.
Es gibt dafür Lösungen, und zwar muss man die Xauthority bemühen und 0:0 an das Programm melden, welches um 17:15 aufpoppen soll – da man das so selten macht, hat man die Syntax nicht im Kopf und ist verstimmt. Im Ubuntuusers.de-Wiki ist, unter Fenster öffnet sich nicht, vermerkt wie es geht (noch etwas nach unten scrollen).
Auch ich habe schon oft darauf verwiesen, aber jetzt, bei meiner oberflächlichen Beschäftigung mit Orage eine einfache Alternative gefunden. Und darum geht es hier. :)
Also, wenn man ein Programm, dass die grafische Oberfläche braucht, starten will, dann geht man zu Orage. Hat man oben rechts in der Systemleiste eine Uhr laufen, dann bringt ein Doppelklick darauf wahrscheinlich Orage im Kalendermodus in den Vordergrund.

Was wir jetzt noch brauchen ist aber ein praktisches Beispiel, und deswegen kommen wir einfach nicht auf den Punkt, sondern holen nochmal auf einem zweiten Pfad aus.
Man hat ja unter /var/log/ jede Menge Logdateien liegen, die man nie anschaut, weil man sie nicht versteht. Geht was schief mit dem System wird man dann von naseweisen Linuxgurus gefragt, was das Syslog sagt. Der 0-8-15 User weiß nicht mal, dass es sowas gibt. Also ls -l /var/log/syslog eingeben:
> ls -l /var/log/syslog
-rw-r----- 1 syslog adm 71855 Feb 23 01:07 /var/log/syslog
Mit 70kb ein ganz schön fettes Ding.
Mit less /var/log/syslog (less is more) kann man sich den Inhalt ansehen. Wenn etwas schiefläuft, dann oft richtig, und die gleiche Nachricht taucht 100fach im Logfile auf. Mit einer Länge von 3 Zeilen a 150 Zeichen kommt man leicht auf 45.000 Zeichen. Die Nachrichten zu entziffern ist schon eine Wissenschaft für sich, aber wenn man regelmäßig reinschaut kann man ja einzelnen Nachrichten nach und nach auf den Grund gehen. Und man bemerkt vielleicht, wenn das Logfile plötzlich ganz anders ausschaut.
Früher hatte ich ewig, über unterschiedlichste Distributionen und Versionen hinweg Meldungen im Syslog, dass 3 Systemfonts nicht gefunden werden konnten. Im laufenden Betrieb hat sich aber nie ein Fehler geäußert. Einmal wollte ich sie loswerden und habe das Netz durchsucht, aber weder fand ich einen Ort, um die Fonts endlich runterzuladen, noch einen Trick die Meldungen loszuwerden.
Überflüssige Fehlermeldungen sind nämlich ein Problem: Sie erhöhen das Rauschen, den Heuhaufen, in dem man dann die Nadel nicht findet.
Ein anderer Unbill war eine fehlerhafte Druckerdatei, bei hoch gesetztem Loglevel des Druckerdaemons. Der hat dann gleich 100 Zeilen Fehlerprotokoll ins Log geschrieben, und das minutenweise. Das wurde rasch zu einem Dateigrößenproblem.
Jetzt gibt es auch den wunderbaren Daemon logrotate. Der rotiert das Logsystem, und zwar insofern, als die Logdatei von gestern zu xy.0.log umbenannt wird, die von gestern, die xy.0.log hieß wird xy.1.log genannt – sinnvollerweise in umgekehrter Reihenfolge, und so weiter, und die älteste wird gelöscht. Und was älter als gestern ist wird gezippt, und da diese Logdateien oft hochgradig redundant sind, sind die gezippten Dateien oft wesentlich kleiner, als die frischen, ungezippten. Weil sysadmins so oft in diese Dateien schauen müssen, gibt es extra das Programm zless, dass ein less auf gezippte Texte ausführt.
Wir beenden den Exkurs zu den Logdateien und kommen zurück zum Thema. Als auf Stackexchange jemand fragte, wie ein grafisches Programm zeitgesteuert startet – er wollte etwas ähnliches wie Logdateien ansehen, dachte ich nach, wie ich das lösen würde, aber konnte ihm nicht konkret helfen, weil er eine Lösung für MacOS sucht. Aber so kam ich auf die Idee, 1x täglich könnte ich mir die Syslogdatei vorlegen, und wollte sehen, ob sich das nicht mit Orage lösen lässt, wo ich bemerkt hatte, dass man zur Benachrichtigung ein Programm starten kann.
Dieses Programm kann man leicht selbst schreiben, und von Orage starten lassen. Die Idee ist dabei, die oft ellenlange Ausgabe der Logdatei zu kürzen, so dass ähnliche Meldungen nur noch einmal auftauchen. Meine Logdatei zeigt etwa sowas an:
Feb 22 07:35:02 tux201t colord[1154]: (colord:1154): Cd-WARNING **: failed to get session [pid 9723]: Kein passendes Gerät bzw. keine passende Adresse gefunden
Feb 22 07:35:02 tux201t colord[1154]: message repeated 5 times: [ (colord:1154): Cd-WARNING **: failed to get session [pid 9723]: Kein passendes Gerät bzw. keine passende Adresse gefunden]
Feb 22 07:35:10 tux201t anacron[9507]: Job `cron.daily' terminated
Feb 22 07:35:10 tux201t anacron[9507]: Normal exit (1 job run)
Feb 22 07:39:33 tux201t kernel: [1253876.380868] sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
Feb 22 07:39:33 tux201t kernel: [1253876.380875] sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
Feb 22 07:39:33 tux201t kernel: [1253876.380877] sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
Feb 22 07:39:33 tux201t kernel: [1253876.380882] sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
Feb 22 07:49:01 tux201t CRON[10242]: (stefan) CMD (date >> $HOME/foo.dat)
Feb 22 07:49:33 tux201t kernel: [1254476.385144] sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
Feb 22 07:49:33 tux201t kernel: [1254476.385154] sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
Feb 22 07:49:33 tux201t kernel: [1254476.385160] sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
Feb 22 07:49:33 tux201t kernel: [1254476.385167] sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
Feb 22 07:59:33 tux201t kernel: [1255076.377070] sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
Feb 22 07:59:33 tux201t kernel: [1255076.377081] sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
Feb 22 07:59:33 tux201t kernel: [1255076.377086] sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
Feb 22 07:59:33 tux201t kernel: [1255076.377093] sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
Feb 22 08:00:01 tux201t CRON[10538]: (stefan) CMD (/home/stefan/bin/blogcounter.sh -w >> /home/stefan/.bloglog)
Feb 22 08:09:33 tux201t kernel: [1255676.380279] sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
Feb 22 08:09:33 tux201t kernel: [1255676.380286] sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
Feb 22 08:09:33 tux201t kernel: [1255676.380289] sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
Feb 22 08:09:33 tux201t kernel: [1255676.380293] sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
Feb 22 08:17:01 tux201t CRON[11053]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Feb 22 08:17:01 tux201t cron[926]: Please install an MTA on this system if you want to use sendmail!
Feb 22 08:17:01 tux201t CRON[11052]: (root) MAIL (mailed 107 bytes of output but got status 0x00ff from MTA#012)
Bis auf die Uhrzeit wiederholt sich vieles, und bis auf die magischen Zahlen in Backsteinklammern.
Das kann man mit sed, dem StreamEDitor, rausfiltern. Außerdem brauche ich die Angabe ‚tux21t‘, meinen Rechnernamen nicht – da ist nur der eine.
sed -r 's/.* tux201t//;s/kernel: .[0-9.]+. /kernel: /;s/CRON.[0-9]+./CRON/' /var/log/syslog
colord[1154]: (colord:1154): Cd-WARNING **: failed to get session [pid 9723]: Kein passendes Gerät bzw. keine passende Adresse gefunden
colord[1154]: message repeated 5 times: [ (colord:1154): Cd-WARNING **: failed to get session [pid 9723]: Kein passendes Gerät bzw. keine passende Adresse gefunden]
anacron[9507]: Job `cron.daily' terminated
anacron[9507]: Normal exit (1 job run)
kernel: sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
kernel: sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
kernel: sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
kernel: sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
CRON: (stefan) CMD (date >> $HOME/foo.dat)
kernel: sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
kernel: sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
kernel: sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
kernel: sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
Das ist kürzer, und jetzt sind viele Zeilen identisch. Mit | sort | uniq -c | sort -r -n kann man die Ausgabe sortieren, mit uniq die wiederholten Zeilen löschen, uniq -c zählt dabei die gelöschten Duplikate, ein weiteres sort -r -n sortiert dann numerisch und reverse, das heißt hier absteigend.
110 kernel: sd 6:0:0:0: [sdb] tag#0 Sense Key : Hardware Error [current] [descriptor]
110 kernel: sd 6:0:0:0: [sdb] tag#0 FAILED Result: hostbyte=DID_ERROR driverbyte=DRIVER_SENSE
110 kernel: sd 6:0:0:0: [sdb] tag#0 Add. Sense: No additional sense information
109 kernel: sd 6:0:0:0: [sdb] tag#0 CDB: ATA command pass through(16) 85 06 20 00 00 00 00 00 00 00 00 00 00 00 e5 00
18 CRON: (stefan) CMD (/home/stefan/bin/blogcounter.sh -w >> /home/stefan/.bloglog)
18 CRON: (stefan) CMD (date >> $HOME/foo.dat)
18 CRON: (root) MAIL (mailed 107 bytes of output but got status 0x00ff from MTA#012)
18 CRON: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
18 cron[926]: Please install an MTA on this system if you want to use sendmail!
8 dbus[986]: [system] Activating via systemd: service name='org.bluez' unit='dbus-org.bluez.service'
7 org.freedesktop.Notifications[1801]: /home/stefan/.cache/xfce4-notifyd-theme.rc:1: error: scanner: unterminated string constant
Jetzt wollen wir noch die Ausgabe an ein simples Grafikprogramm weitergeben. Hier bietet sich Zenity an, welches bei Xubuntu dabei ist – eine Alternative wäre xdialog – das wir mit der Größe 1400×600 starten, und für das wir ein paar Label festlegen.
zenity --list --text="Syslog messages" --column="logmsg" --width=1400 --height=600
Zenity war hier schon Thema und soll nicht näher besprochen werden. man zenity oder zenity --help verraten das wichtigste in Kürze. Auch im Ubuntuusers.de führt in den Umgang ein.
Komplett sieht unser Programm also jetzt so aus:
#!/bin/bash
#
condense syslog ((c) GPLv3)
#
sed -r 's/.* tux201t//;s/kernel: .[0-9.]+. /kernel: /;s/CRON.[0-9]+./CRON/' /var/log/syslog \
| egrep -v "Starting Hostname Service.|Started Hostname Service" | sort | uniq -c | sort -nr | \
zenity --list --text="Syslog messages" --column="logmsg" --width=1400 --height=600
Aufmerksame Leser haben bemerkt, dass sich hier noch ein Kommando eingeschlichen, hat, und zwar egrep -v "A|B" . Mit egrep -v kann man unerwünschte Zeilen ausfiltern, die ein Schlüsselwort enthalten. Diese zwei, durch ein Pipesymbol getrennte Namen A|B sind als A oder B zu lesen, und sind nach Bedarf zu erweitern, A|B|C|D … – so kann man Meldungen, die nur Erfolg verkünden, ausblenden. Wir wollen ja die unangenehmen Heinis identifizieren. Mit der Zeit wächst das sicherlich an, wenn man diszipliniert nach und nach allen Meldungen auf den Grund geht.
Weil die Befehlskette so lang ist, habe ich sie umgebrochen. Dazu benutzt man den Backslash, dem sofort ein Zeilenumbruch folgen muss, dann in der nächsten Zeile fortgesetzt.
Ich nenne sie syslog-view.sh, speichere sie in meinem bin-Dir ~/bin, welches im Pfad ist, und markiere sie mit chmod a+x ~/bin/syslog-view.sh als ausführbar.
Mit syslog-view.sh kann man sie jetzt aufrufen und sollte das auch testen. Bei Fehlern testet man sinnvollerweise erst die Filterung mit sed, dann die sort-Kette in Verbindung, schließlich ob man Zenity mit einer anderen Eingabe so aufrufen kann, und dann die Kombination.
Jetzt kommen wir zum eigentlichen Punkt, den Aufruf durch Orage. Hier sind jetzt die GUI-Freunde in ihrem Element. Wir klicken einen einzelnen Tag an, und kommen zum Tagesfenster. Da wählen wir Ereignis oder Aufgabe – der Unterschied hat sich mir noch nicht erschlossen, und dann, links unter Datei, das Symbol für Neu, das Blatt mit dem Plus.

Wenn wir schwach sind im Entscheiden, dann können wir hier wieder von Ereignis zu Aufgabe wechseln oder zurück. Ich war für Ereignis. Da vergeben wir einen Titel. Ort hat wenig Sinn, aber ich bin kein Orage-Crack, womöglich entgeht mir da was. Und eine Uhrzeit legen wir fest – 18:05 halte ich für eine excellente Entscheidung. Oft bin ich da schon wach.

Rubriken sind wohl interessant, wenn man viel mit Orage verwaltet. Priorität habe ich so gelassen und alles. Dauer 30 Minuten steht auch nur so da.
Nächster Reiter, Erinnerung, es wird spannend! 
Mit 0:0:0 als Erinnerungszeitpunkt verraten wir Orage, dass die Anwendung selbst die Aufgabe ist. Wenn wir ins Konzert wollen, und eine Stunde früher los müssen, dann würden wir da wohl 1 Stunde eintragen. Wir sind von der Sorte hier-und-jetzt. Anwendung wollen wir benutzen, und tragen den Pfad zum Programm und Programmnamen ein. Ob Shellkürzel wie $HOME oder ~/ funktionieren würden habe ich nicht getestet.
Nächster Reiter, Wiederholung:
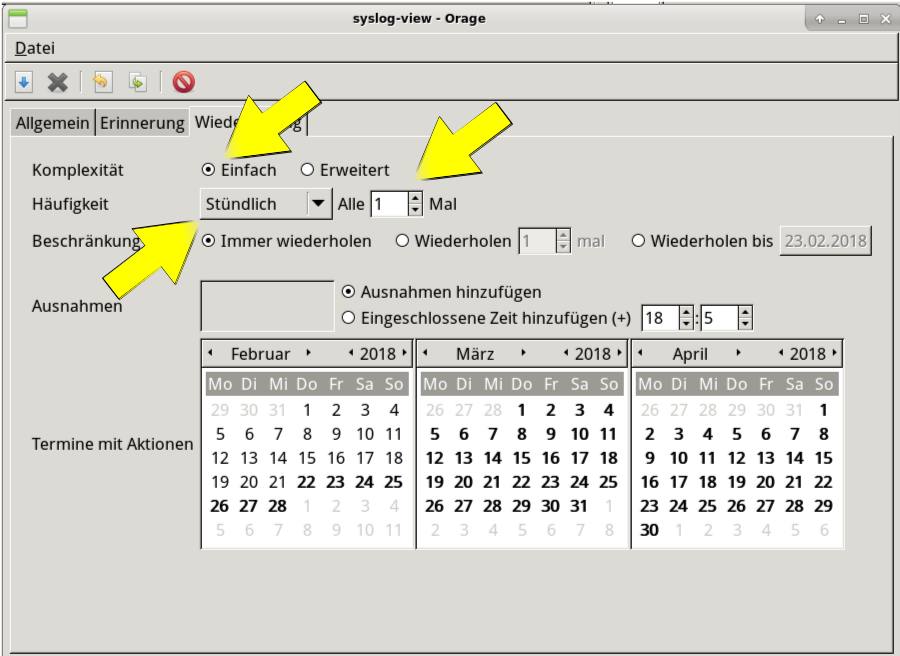
Alle Stunde ist wohl etwas oft. Das hatte ich zum Testen eingestellt. Täglich, wöchentlich, monatlich und jährlich stehen noch zur Auswahl, und man könnte auch 2-wöchentlich oder sowas festlegen. Komplexität bitte selbst erforschen.
Tja, und jetzt poppt täglich mein Logmelder auf, und ich darf mich fragen, was der Colordämon wohl ist, und was er macht. Das Ziel ist es, nach und nach den Meldungen auf den Grund zu gehen, diejenigen zu beseitigen, die ich beseitigen kann, und diejenige auszufiltern, die harmlose Statusmeldungen sind. So dass das Logfile leerer wird, und neue Fehler dann auch auffallen.
Achso – wie sieht es in Zenity aus?

Die Überschrift, man solle was auswählen, kommt vom Listenmodus zenitys. Womöglich kann man sie durch was eigenes ersetzen. Ob man OK oder Abbrechen drückt hat den gleichen Effekt – das Fenster schließt sich. Man könnte bei OK die Ausgabe auffangen und damit was anstellen (automatisierte Googlesuche, etwa, oder Frage eröffnen bei Ubuntuusers.de, oder Email an den persönlichen Linuxguru schicken.)
Ich hatte mal einen Nullmailer installiert; das wozu ist eine andere Geschichte, die hier nicht erzählt werden soll. Dann klappte es nicht mehr, wurde aber auch nicht mehr gebraucht. Daher jedenfalls stammt dieser Eintrag mit 18 Meldungen, ich solle einen MTA (Mail transport agent) installieren. Zenity kann man, meine ich, mitteilen, ob man die Zeilen edieren darf. Ja, das werde ich noch einstellen, wenn Hinweise in den Kommentaren nicht schneller sind, denn so, wie es jetzt ist, kann man schlecht den Text kopieren, um ihn selbst ins Google-Suchfeld einzugeben.