– Bonsaiwutbürger –

Mal wieder was aus dem öffentlichen Raum der Graswurzeldekorierer. Weiterlesen
– Wintermarkt – 
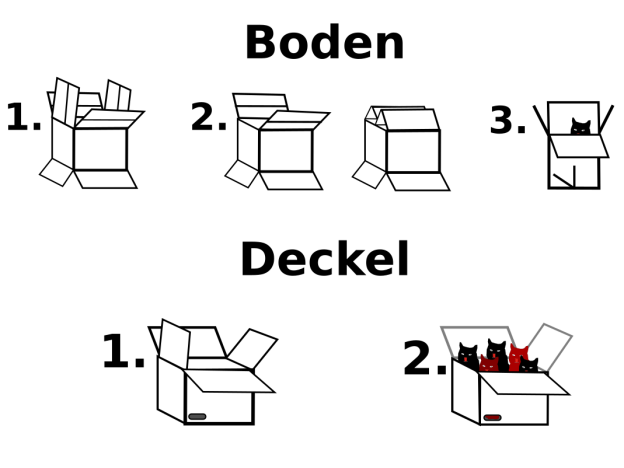
– Karton, HowTo –
– Abgasgaudi –

– pdftotext –

Seit einiger Zeit bin ich stolzer Besitzer der ersten 8 Bände der Kriminalgeschichte des Christentums von Karlheinz Deschner. Die Seitenzahl von über 8000 fand ich jedoch erdrückend und startete einst einen Versuch das PDF in Text umzuwandeln um es mir von Software dann vorlesen zu lassen.
Das Ergebnis war recht erbärmlich. Ich wollte zwar pro Tag etwa 15 Minuten davon zum Einschlafen hören, und wäre damit, wie ich jetzt berechnen konnte, nach weniger als einem halben Jahr durch gewesen, die monotone Computerstimme führt aber dazu, dass man bereits nach 2 Minuten einschläft oder nicht einschläft, aber nach 3 Minuten nicht mehr zuhört, was die Stimme erzählt.
Jetzt habe ich einen zweiten Anlauf genommen und mir ein paar Audioprogramme installiert, die ich vergleichen wollte, und beschlossen den Text bei den übelsten Vertonungen vorher zu präparieren.
Die einfachste Herangehensweise ist es mit dem Befehl
pdftotext deschner.pdf deschner.txt
aus den ca. 50MB PDF ca. 10MB reinen Text zu machen, aber dieser wird dann auf jeder Seite von der Seitenzahl (343), der Kapitelüberschrift, der Bandangabe und von der Seite unten noch mal in Klein ‚Karlheinz Deschner: Kriminalgeschichte des Christentums‘ unterbrochen.
Erst probierte ich mit Sed, dem Streameditor, diese Textstellen zu erkennen und zu löschen, was auch weitgehend klappte, wenn auch nicht optimal. Dann beschäftigte ich mich bereits mit einigen Feinheiten, auf die ich später noch kommen will.
Mit ein wenig Handbuchlesen, ausprobieren und der Zuhilfenahme anderer Programme kann man im ersten Arbeitsgang nämlich schon ein sehr ansehnliches Basisexemplar erzeugen.
mit
xpdf -z 100 deschner.pdf
öffnete ich den ultraschlanken und daher schnellstartenden PDF-Viewer xpdf im Zoommodus 100%. Die 100% sind wichtig, denn vom Screenshot wollen wir die Anzahl Pixel ablesen. Ich schoss also einen Screenshot, nur von der dargestellten Seite – nicht dem umschließenden Programm. Den speicherte ich als deschner.png um ihn mit gimp, dem GNU-Imaage-manipulation-Programm zu öffnen. Dieses hat am Rand Lineale, so dass ich ablesen konnte, wo ich das Dokument beschneiden muss, um das Brimborium (gelbe Pfeile) von Anfang und Ende der Seite loszuwerden. Den abzuschneidenden Teil habe ich vergilbt eingefärbt.
Die kurzen vertikalen Striche sind 10 Pixel, die mittleren 20 Pixel voneinander entfernt. 60 von oben sollte also passen (blaue Pfeile). Unten wären es etwa 820. Allerdings gibt man nicht die untere Koordinate an, sondern die Höhe, also die Differenz zu den 60 von oben, das wären also 760.
Außerdem gilt es die umfangreichen, schlecht les- und hörbaren Quellenangaben zwischen den Kapiteln auszumerzen. Die Seitenzahlen könnte man aus dem Inhaltsverzeichnis nehmen, wenn es eins gäbe – da nicht muss man sich grob in 1000er-Schritten durchs Buch iterieren und dann suchen, wo genau Fußnoten und beginnen und Dank an hilfreiche Leute enden. Mit -f 23 gibt man an, from page 23, mit -l 883 last page 883.
-t für to wäre wohl zu naheliegend gewesen. -x und -y sind für den oberen, linken Punkt zuständig, wo das Ausschneiden beginnen soll – den X-Wert kann man nicht weglassen, nur weil man in X-Richtung nichts wegschneiden will, wie ich feststellen musste, und was wohl bei meinen ersten Experimenten zum frustrierten Abbruch der Experimentierphase führte. -H steht für Height, -W für Width, auch beides nicht weglassbar im Sinne von ’nimm alles‘.
Weitere benutzte Optionen sind:
-raw : keep strings in content stream order
-nopgbrk : don’t insert page breaks between pages
Ich glaube ‚raw‘ braucht es jetzt gar nicht mehr, es hat aber wohl auch nicht geschadet. So hier also die Kommandos gruppiert. Viel Arbeit, aber wir reden ja auch von über 8000 Seiten:
pdftotext -f 23 -l 883 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.1.txt pdftotext -f 1099 -l 1840 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.2.txt pdftotext -f 1984 -l 2946 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.3.txt pdftotext -f 3102 -l 3890 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.4.txt pdftotext -f 4042 -l 5032 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.5.txt pdftotext -f 5147 -l 6050 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.6.txt pdftotext -f 6161 -l 6977 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.7.txt pdftotext -f 7065 -l 7799 -raw -nopgbrk -y 60 -x 0 -H 760 -W 560 deschner.pdf d.8.txt
Zu den Vorleseprogrammen benötigt es ein wenig Vorwissen: Diese zerlegen einen Text in Silben und versuchen die Stimme an Wortgrenzen und Satzzeichen zu sinnvollen Lauten bewegen, die vorhergehenden und nachfolgenden Silben berücksichtigend. Das ist über verschiedene Sprache ein ähnliches Problem, aber natürlich von Sprache zu Sprache verschieden.
Was die Programme nicht kennen, das ist die Aussprache ganzer Wörter. Alles wird synthetisch produziert und ist daher für verschiedene Probleme wie geschaffen.
Ausländische Wörter werden gar nicht erst erkannt, und alles so ausgesprochen wie die eingestellte Sprache nun mal ist, hier also Deutsch. Es gibt zum Glück nur wenige englische Phrasen. Häufiger aber Lateinische Namen. Überhaupt Namen! David klingt wie Dafid. In Atheisten wird das ei wie in Frühstücksei gesprochen. 1953 wird als tausend-neunhundert-dreiundfünfzig gesprochen. Kontexterkennung ist auch Glückssache. Häufig finden sich Zeitspannen wie Regentschaften oder Lebenszeiten (523-569) und da liest der Text stumpf die zwei Zahlen vor, zum Glück ohne Klammern. Eckige Klammern werden aber als ‚eckige Klamer 319‘ gelesen. Fußnoten (roter Pfeil) werden als Zahl vorgelesen. Häufig verwendet Deschner die 3-Punkt-Ellipse … (anderer roter Pfeil)- da macht die Stimme eine für mich zu lange Pause.
Die häufigsten Ärgernisse habe ich mit einem Sedscript auszumerzen oder verbessern versucht. Oft kommt auch nach einem Absatz ein Name in Klammern, eine Quelle. Die habe ich, soweit möglich, gelöscht, das heißt, wenn es nur ein Zeichenfolge war (Wagner), aber nicht, wenn es mehrere Token waren, weil es auch Nebengedanken in Klammern gibt, die ich nicht opfern wollte.
Kontext ist auch Glückssache. S. 47 wird nicht zu Seite 47, andere Abkürzungen werden aber teilweise erkannt und aufgelöst.
Hier mein unfertiges Script für die Details:
s/David/Dawied/
#«
# Fußnoten im Audiostrom nicht hilfreich ("bla fasel.49", ... foobar«69, bar foo 96.)
s/\.[0-9]+$/./
s/[^ 0-9][0-9]+\././
s/«[0-9]+$/«/
#
# (870–849) wird nicht als "870 bis 849" vorgelesen, sondern als "870 849"
s/([0-9]+)–([0-9]+)/\1 bis \2/
#
# unverständlich, "Vau Char":
s/v\. Chr\./vor Christus/g
s/n\. Chr\./nach Christus/g
#
# Störende Quellen (Maier) löschen, löscht aber auch hilfr. Anmerkungen "Berlin (Deutschland)"
s/\([A-Z][a-z]+\)//
#
# sog. heilige
s/\Wsog. /sogenannte/
#
# (S. 247) löschen (vgl. S. 245) (S. 312 f) (S. 999 ff)
s/(vgl\. )?S\. [0-9]+ ?f?f?\)//
#
# Karl I. (Karl Ih statt Karl der Erste)
#
# 1955 wird als eintausendneunhundert55 vorgelesen
s/1([0-9])([0-9]{2})/1\1-hundert \2/g
#
Die erzeugten Dateien sind alle etwa 1MB groß. Das Vertonungsprogramm soll aber nur Schnipsel von bis zu ca. 35kb abspielen können. Also müssenn wir jede Datei in ca. 30 Teile zerlegen, oder sagen wir 40, um auf der sicheren Seite zu sein.
Mit
for i in {1..8}; do sed -rf feinjust.sed -i d.$i.txt ; done
lassen wir die Sedbefehlskaskade auf die 8 Dateien los. -r steht für regexp, und erspart uns in der Steuerdatei die runden Klammern zu maskieren. -f liest die Sedbefehle aus der folgenden Datei (file), -i ändert diese an Ort und Stelle (in place), so dass wir die Ausgabe nicht in eine neue Datei lenken müssen.
Die Zeilenlänge ermitteln wir mit wc (word count) und splitten die Bücher in je 40/41 Teile auf, 41, weil die Division einen Rest lassen kann, der bei der Multiplikation dann beim Buch 40 zu kurz kommt (nur einmal geht es genau auf, da ist Datei d.3.41.txt nämlich d.3.41.txt dann leer:
#!/bin/bash
#
#
blist=($(wc -l d.?.txt))
echo ${blist[@]}
# 21683 d.1.txt 18436 d.2.txt 23760 d.3.txt 19148 d.4.txt 23549 d.5.txt 22436 d.6.txt 20239 d.7.txt 18204 d.8.txt 167455 insgesamt
for buch in {1..8}
do
zeilen=${blist[$((2*buch-2))]}
faktor=$((zeilen/40))
echo "Zeilen: $zeilen Faktor: $faktor"
for part in {1..41}
do
sed -n "$(((part-1)*faktor+1)),$((part*faktor))"p d.$buch.txt > d.$buch.$part.txt
done
done
Jetzt haben wir 8×41-1 Dateien. Wir prüfen noch, ob keine zu groß wurde:
find -name „d.?.*.txt“ -size +34k -ls
Nein, alles bestens. mit +29k kann man sehen, dass der Befehl funktioniert.
Fast sind wir soweit, dass wir was hören. :)
Mit einer Schleife gebe ich die Texte an das Vorlesescript weiter und gebe dabei die Uhrzeit, den Dateinamen und deren Inhalt aus. So kann man doch mitlesen und kontrollieren, wenn unverständliches kam. Man sieht, dass Die Dateien mitten im Satz zerschnitten sind – das ist bei ½-stündigen¹ Audiofiles verschmerzbar und mir zu viel Arbeit, es benutzerfreundlicher zu machen.
for i in {15..16}; do echo; ls d.1.$i.txt; date; cat d.1.$i.txt; textlesen.sh d.1.$i.txt; done; date
d.1.15.txt
Di 24. Nov 03:20:22 CET 2015
lecker. Sie sind voll von »Dünkel« und »prunkenden
Phrasen«, sind geil und lügen. Ihre Einrichtungen,
ihre Sitten, ihre Religion und Wissenschaft, alles ist
»albern«, »vielfältige Torheit«, »wahnwitzig«.
Fehlt noch das Vorlesescript textlesen.sh:
#!/bin/bash
pico2wave -l=de-DE -w=/tmp/${1}.wav "$(cat ${1})"
# aplay /tmp/${1}.wav # && rm /tmp/${1}.wav
vlc /tmp/${1}.wav # && rm /tmp/${1}.wav
pico2wave wandelt mit language=deutsch -writing-to /tmp/$1.wav um, was mit cat aus der übergebenen Datei gelesen wird.
Erst hörte ich es mit play an, aber bei vlc habe ich einen Knopf um die Ausgabe anzuhalten, kann zurückspringen usw.
Das Ergebnis ist noch immer hölzern, aber man kann es zur Not anhören. :) Vielleicht probiere ich noch weitere text-to-speech-Lösungen (tts) bzw. Sprachsynthesizer oder finde andere Verbesserungen.
Empfehlungen werden gerne entgegen genommen, bevorzugt natürlich freie Software für Linux.
¹ oben war von ¼-stündigen Teilen die Rede. Das erste Skript erzeugte auch solch kürze Dateien, weil ich grober geschätzt hatte mit der Zeilenzahl. Mit dem Wissen, dass die Dateien alle nur ca. 15kb groß werden habe ich jetzt die Zeilenzahl erhöht und so längere Stücke erhalten.
– Aufstehen! –
oder, aus der Serie
Rätsel des Alltags:

– Er ist wieder da –
(und mit ihm:)

– Da lacht die Schweiz –

– Was kann man jetzt noch essen? –
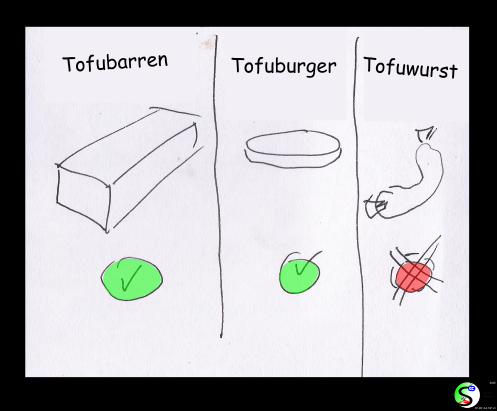
Keine Sorge – die meisten Sachen sind nach wie vor unbedenklich.
